To state the problem of classical parameter estimation mathematically, let us define the following:
- x[n] ≡ observation data at sample time n
- x = [x[0] x[1] … x[N - 1]]T ≡ vector of N observation samples (N-point data set)
- p(x,θ) ≡ mathematical model (i.e., PDF) of the N-point data set parameterized by θ
The problem is to find a function of the N-point data set which provides an estimate of θ, that is
![]()
where 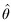 is an estimate of θ and g(x) is known as the estimator function.
is an estimate of θ and g(x) is known as the estimator function.
Once a candidate estimator function g(x) is found, then one usually asks the following questions:
- How close will be to θ (i.e., how good or optimal is the estimator)?
- Are there better estimators (i.e., closer to the value to be estimated) ?
To measure the goodness of an estimator, one need to define a suitable cost function C(θ, ) which essintially captures the difference between the estimated and the true value of the parameter over the range of interest. The typical cost factors used are thequadratic error, the absolute error and the uniform (Hit-or-Miss) cost functions.
In classical (nonrandom) parameter estimation case, the natural optimazation criterion is minimization of the mean square error:
![]()
But often this criterion does not yield a realizable estimator, i.e., the one which can be written as functions of the data only:
![]()
However although [E() - θ]² is a function of θ, the variance of the estimator var() is only a function of data. Thus an alternative approach is to assume E( ) - θ = 0 (i.e., bias is zero) and minimize var(). This produces the minimum variance unbiased estimator (MVUE).