The Genetic code
Since there are 20 different kinds of amino acids in proteins and only four kinds of nucleotides in DNA, the relationship between the gene and its most elementary functional product, i.e., between DNA and protein, can hardly be interpreted through a code of one nucleotide = one amino acid. A coding sequence of two nucleotides for one amino acid, or a doublet code, would produce only 16 possible coding combinations, or codons . Codons are group of nucleotides that specifies one amino acid. By the genetic code (George Gamov, 1954), we mean, a collection of base sequences (codons) that correspond to each amino acid and to translation signals. A codon size of three nucleotides for one amino acid are triplet codon seems more likely, since it produces 64 possible codons, however, only 20 amino acids need to be coded, 44 codons in a triplet code seem to be superfluous. To account for the excess of codons beyond the necessary 20, we can suppose that more than one codon can code for a particular amino acid. For example, if each kind of amino acid were coded by three different possible codons, 60 possible codons would be accounted for. A code in which there is more than one codon for the same amino acid, is called degenerate . It is also possible that some or all of the codons in excess of 20 do not code for any amino acid and are therefore nonsense codons.
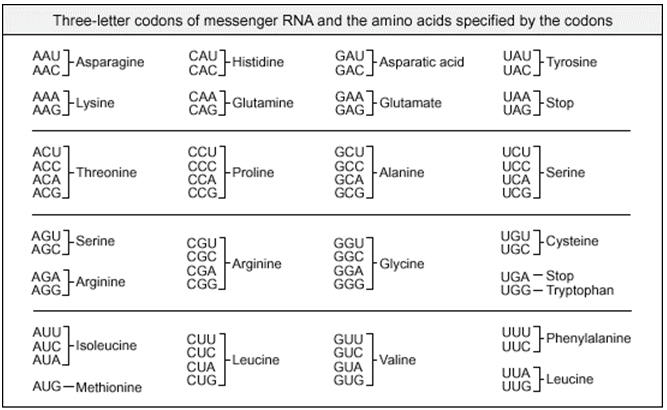
Fig. 8. Genetic Code.
The genetic code has following general properties, mostly applicable to the genes of all the organisms:
Genetic code is triplet. As discussed earlier, singlet and doublet codons cannot form 20 combinations, which is the minimum requirement, therefore triplet codon is a necessity, so that all the amino acids must be coded.
Genetic code is non-overlapping. During translation, the codons are read one after another, in a sequence. One base of a codon is not used by the other codons. Therefore, if there are six bases, they will code for two amino acids only. e.g.; in case of non-overlapping, a gene sequence of UUUCCC only two amino acids will be coded, phenylalanine (UUU) and proline (CCC), whereas for an overlapping code, more than two amino acids could be coded, phenylalanine (UUU), serine (UCC) and proline (CCC).
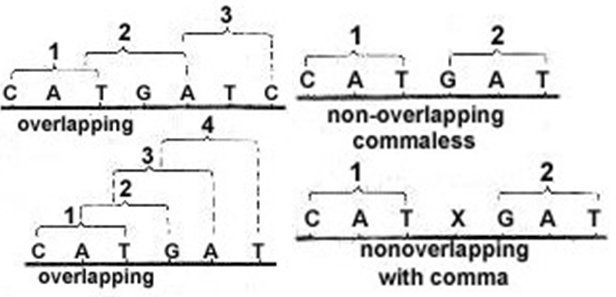
Fig. 9. Overlapping and non-overlapping genetic code
Genetic code is commaless. The bases are read one after the other in the codons, i.e., no bases or codons are reserved for punctuation or comma. When the first amino acid is coded, the second will be coded by the next three bases immediately, and no base will be wasted to serve as a comma. Once the translation begins, the codons are read one after the other with no break or demarcating signals in between them.
Genetic code is non-ambiguous. Each codon has a particular amino acid for coding, and it will code for that amino acid only. There is one to one relationship between codon to amino acid. However, there is an exception, AUG codes for methionine and GUG codes for valine, but if AUG is absent, then GUG codes for methionine, as starting codon for protein synthesis. In an ambiguous code, one codon can code for more than one amino acid.
In certain rare cases, the genetic code is found to be ambiguous i.e, some codons codes for different amino acids under different conditions, e.g. in streptomycin sensitive strain of E.coli the codon UUU normally codes for phenylalanine, but it may also code for isoleucine, serine when treated with streptomycin. This ambiguity is enhanced at high Mg ion concentration, low temperature and the presence of ethyl alcohol.