

Contents
System Specifications
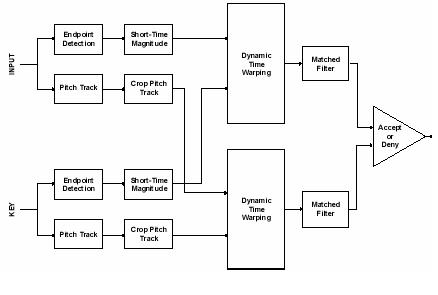
Working:
4.1 Endpoint Detection
The implementation for the speaker verification system first addresses the issue of finding the endpoints of speech in a waveform. Endpoints are the points on the time axis at which the actual speech signal starts and terminates. The codes algorithm finds the start and end of speech in a given waveform, allowing the speech to be removed and analyzed. It is important to note that this algorithm gives the entire region where speech exists in an input signal. This speech could include voiced regions as well as unvoiced regions. Voiced speech includes hard consonants such as "ggg" and "ddd", while unvoiced speech includes fricatives such as "fff" and "sss". For the short-time magnitude of a speech signal, it is necessary to include all speech which would be located by this algorithm. However, for short-time pitch, one is only concerned with voiced regions of speech. As a result, this algorithm is not used, and instead, we use the energy in the signal to find the voiced and unvoiced regions of the pitch track.4.2 Dynamic Time Warping (DTW)
"Dynamic Time Warping" (DTW) is a procedure which computes a non-linear mapping of one signal onto another by minimizing the distances between the two signals i.e the input signal and the key signal. Suppose a speaker verification system has a password of "Project". If the user says "Prrroooject" instead of Project, here the rate of speech has varied during the input. Obviously, a simple linear squeezing of this longer password will not match the key signal because the user slowed down the first syllable while he kept a normal speed for the "ject" syllable. We need a way to non-linearly time-scale the input signal to the key signal so that we can line up appropriate sections of the signals (i.e. so we can compare "Prrrooo" to "Pro" and "ject" to "ject"). The solution to this problem is "Dynamic Time Warping" (DTW).4.3 Feature Extraction
The final implementation for our speaker verification system includes matched filtering the pitch and magnitude of a signal. By comparing the short-time magnitude and short-time pitch of two speech signals, we are separating the waveforms into their slowly and quickly varying components, respectively, thus eliminating the problem of aligning the phase of the two input waveforms. short-time processing methods => short segments of the speech signal are isolated and processed as if they were short segments from a sustained sound with fixed (non-time-varying) properties.4.3.1 Short-Time Magnitude
One portion of the final implementation is the comparison of the short-time magnitude of two speech signals. Using an endpoint detection process, the speech is selected from the two input waveforms. Then, their short-time magnitudes are determined.4.3.2 Short-Time Frequency
A simple model of the human vocal tract is a cylinder with a flap at one end. When air is forced through the tract, the vibration of the flap is periodic. The inverse of this period is known as the fundamental frequency, or pitch. This frequency, combined with the shape of the vocal tract, produces the tone that is your voice. Variations in people's vocal tracts result in different fundamentals even when the same word is said. Therefore, pitch is another characteristic of speech that can be matched. For short-time pitch, one is only concerned with voiced regions of speech. As a result, the end point detection process is not used, and instead, we use the energy in the signal to find the voiced and unvoiced regions of the pitch track.4.4 Training
When a speaker attempts to verify himself with this system, his incoming signal is compared to that of a "key". This key should be a signal that produces a high correlation for both magnitude and pitch data when the authorized user utters the password, but not in cases where: the user says the wrong word (the password is forgotten)
an intruder says either the password or a wrong word
To develop such a key, the system is trained for recognition of the speaker. In this instance, the speaker first chooses a password, and it is acquired five separate times. The pitch and magnitude information are recorded for each. The signal that matches the other four signals best in both cases is chosen as the key.
4.5 Verification
Once a key has been established, an authorization attempt breaks down into the following steps:1. The person speaks a password into the microphone.
2. The short-time magnitude of the signal is found and recorded, as is the pitch track.
3. Each is cropped and dynamically time warped so that (possible) corresponding points on the signals are aligned.
4. Now that the signals rest on top of each other, matched filter (for both magnitude and pitch) to determine a numerical value for their correlation.
5. These numbers are compared to the thresholds set when the key was first created. If both the magnitude and pitch correlations are above this threshold, the speaker has been verified.
6. Allow user to enter top-secret hangout.

