| |
Types of Units
 The relevant TU that is retrieved will match the source text segment. What is a text segment? From the TM perspective, a segment is a smaller unit of the source text like a sentence or a word. The basis of TM technology is the splitting of texts into various segments and then trying to align them. The process of splitting up a text into segments or smaller units is called segmentation. The most common unit is the sentence, but there are systems that consider headings, lists etc also as segments. Problems in alignment or matching can occur if the SL and TL do not match in terms of segments. For example, a language like English which is a Latin-based script and Chinese will be very difficult to align. These languages differ in segmentation or the way in which they can be split up into smaller units. The relevant TU that is retrieved will match the source text segment. What is a text segment? From the TM perspective, a segment is a smaller unit of the source text like a sentence or a word. The basis of TM technology is the splitting of texts into various segments and then trying to align them. The process of splitting up a text into segments or smaller units is called segmentation. The most common unit is the sentence, but there are systems that consider headings, lists etc also as segments. Problems in alignment or matching can occur if the SL and TL do not match in terms of segments. For example, a language like English which is a Latin-based script and Chinese will be very difficult to align. These languages differ in segmentation or the way in which they can be split up into smaller units.
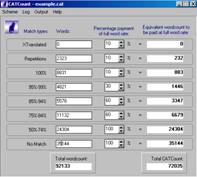
But the ways in which it matches the source text varies. The matches are classified as ‘exact’, ‘full’ and ‘fuzzy’. An exact match means that the source text to be translated is identical to a source text segment that is stored in TM. This does not require any change even in formatting and can be used as it is. A full match implies that the segment stored in the memory is almost identical, with a few variables like date and time that can be changed easily. A fuzzy match is one where the source text is similar to the one stored in memory, but the matching segment can be used only with a bit of editing.A fuzzy match comes closest to the human process of choosing an equivalent for a word or sentence in translation. In computer terminology, this is a much more sophisticated technology than the exact or full matches.
TM technology has developed a great deal since its inception. It used to be able to retrieve only sentences initially, but second generation technology was able to retrieve fuzzy matches. Third generation TM technology that is aiming for matches at the sub-sentence level is emerging now. This is because translation theorists have pointed out that a translator in actual practice might not consider the sentence as a basic unit. But as O’Hagan observes, an ideal TU is yet to be identified.
|
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
|
|
|
|