1-1.4 Genetic code:
The genetic code is the set of instructions that translates the information encoded in genetic material (mRNA or DNA sequences) into proteins (amino acid sequences) by living cells.
- The genetic code is a triplet code (i.e. a group of three adjacent nucleotides) called codon. This three nucleotide codon in nucleic acid sequence specifies a single amino acid. However, genetic code in human mitochondria differs from the standard nuclear genetic code.
- Epigenetic effects, however is not stored using the genetic code. Besides all organisms have DNA that contains regulatory sequences, intergenic segments, chromosomal structural areas and other non-coding DNA that can contribute greatly to phenotype.
- These codons are always written with the 5′-terminal nucleotide to the left.
- The code is unambiguous i.e. each triplet specifies only a single amino acid.
- The genetic code is degenerate i.e. more than one triplet codon can code for a single amino acid. (61 codons code for 20 amino acids)
- Three codons do not specify any amino acid but acts as terminal sites (stop codons), signalling the end of protein coding sequence. They are namely UAA (Ochre), UAG (Amber) and UGA (Opal).
- AUG is an initiation codon that signals the initiation of translation and also codes for methionine. In some mRNA, GUG and UUG also act as initiation codon.
- The genetic codes for each 20 amino acids were defined by pioneering works of Marshall W. Nirenberg and Har Gobind Khorana in 1964.
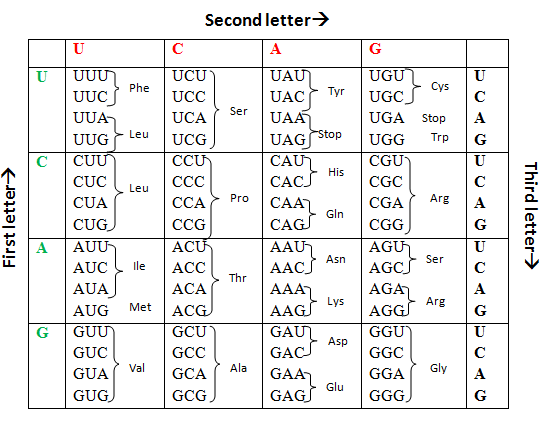
Table 1-1.4: Genetic code