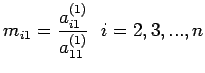
![\begin{displaymath}\left[%
\begin{array}{ccccc}
a_{11}^{(1)} & a_{12}^{(1)} &...
...} \\
. \\
. \\
b_{n}^{(2)} \\
\end{array}%
\right] \end{displaymath}](img115.png)
![\begin{displaymath}A^{(k)}=\left[%
\begin{array}{cccccccc}
a_{11}^{(1)} & a_{...
..._{nk}^{(k)} & . & . & a_{nn}^{(k)} \\
\end{array}%
\right]
\end{displaymath}](img120.png)
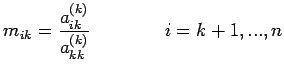 |
(1) |
| (2) |
![\begin{displaymath}\left[%
\begin{array}{ccccc}
a_{11}^{(1)} & . & . & . & a_...
... . \\
. \\
. \\
b_{n}^{(n)} \\
\end{array}%
\right]\end{displaymath}](img127.png)
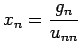
![$\displaystyle x_k=\frac{1}{u_{kk}}[g_k- \sum\limits_{j=k+1}^n u_{kj}x_j]\,\,\,\ , \, k=n-1,n-2, ...1$](img131.png)
![\begin{displaymath}[A/b]=\left[%
\begin{array}{ccc\vert c}
1 & 2 & 1 &0\\
2 & 2 & 3 &3\\
-1 & -3&0 & 2 \\
\end{array}%
\right]\end{displaymath}](img135.png)
![\begin{displaymath}\left[%
\begin{array}{ccc\vert c}
1 & 2 & 1 & 0 \\
2 & ...
... & 3 \\
0 & 0 & 1/2 & 1/2 \\
\end{array}%
\right]=[U/g]
\end{displaymath}](img136.png)
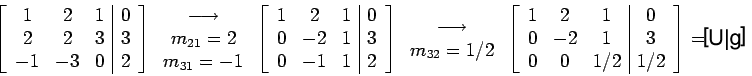
![\begin{displaymath}L=\left[%
\begin{array}{cccccc}
1 & 0 & 0 & . & . & 0 \\
...
...\
m_{n1} & m_{n2} & . & . & . & 1 \\
\end{array}%
\right]\end{displaymath}](img138.png)
![\begin{displaymath}(LU)_{ij}=[m_{i1},...m_{i,i-1},1,0,..0]\left[%
\begin{array}...
...{ij} \\
0 \\
. \\
. \\
0 \\
\end{array}%
\right]\end{displaymath}](img140.png)
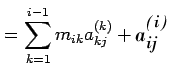
![$\displaystyle =\sum\limits_{k=1}^{i-1}[a_{ij}^{(k)}-a_{ij}^{(k=1)}]+a_{ij}^{(i)}$](img144.png)
![\begin{displaymath}L=
\left[%
\begin{array}{ccc}
1 & 0 & 0 \\
2 & 1 & 0 \...
...\\
0 & -2 & 1 \\
0 & 0 & 1/2 \\
\end{array}%
\right]
\end{displaymath}](img149.png)
![\begin{displaymath}\left[%
\begin{array}{ccc\vert c}
.7290 & .8100 & .9000 & ...
... \\
1.331 & 1.210 & 1.100 & 1.000 \\
\end{array}%
\right]\end{displaymath}](img160.png)
![\begin{displaymath}\left[%
\begin{array}{ccc\vert c}
.7290 & .8100 & .9000 & ...
...\\
0.0 & -.2690 & -.5430 & -.2540 \\
\end{array}%
\right]\end{displaymath}](img162.png)
![\begin{displaymath}\left[%
\begin{array}{ccc\vert c}
.7290 & .8100 & .9000 & ...
...4 \\
0.0 & 0.0 & .02640 & .008700 \\
\end{array}%
\right]\end{displaymath}](img164.png)
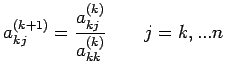
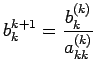
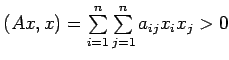 for all
for all 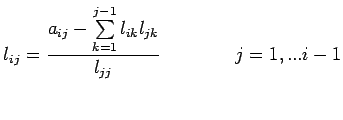
![$\displaystyle l_{ii}=[a_{ii}-\sum\limits_{k=1}^{i-1}l^2_{ik}]^{1/2}$](img197.png) |
(5) |
| (6) |
![\begin{displaymath}A=\left[%
\begin{array}{ccc}
1 & 1/2 & 1/3 \\
1/2 & 1/3 & 1/4 \\
1/3 & 1/4 & 1/5 \\
\end{array}%
\right]\end{displaymath}](img200.png)
![\begin{displaymath}
L=\left[%
\begin{array}{ccc}
1 & 0 & 0 \\
1/2 & 1/2\s...
...
1/3 & 1/2\sqrt{3} & 1/6\sqrt{5} \\
\end{array}%
\right] \end{displaymath}](img201.png)
![\begin{displaymath}\hat{L}=\left[%
\begin{array}{ccc}
1 & 0 & 0 \\
1/2 & 1...
...
0 & 1/12 & 0 \\
0 & 0 & 1/180 \\
\end{array}%
\right]
\end{displaymath}](img202.png)
![\begin{displaymath}A=\left[%
\begin{array}{ccccccc}
a_1 & c_1 & 0 & 0 & . & ....
...b_n & a_n \\
\end{array}%
\right],\mbox{ with } det(A)\neq 0\end{displaymath}](img205.png)
![\begin{displaymath}=\left[%
\begin{array}{cccccc}
\alpha_1 & 0 & . & . & . & ...
... & 1 & r_{n-1} \\
& & & & 0 & 1 \\
\end{array}%
\right]
\end{displaymath}](img207.png)
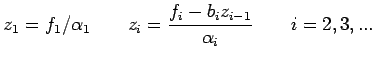
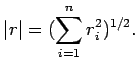
| (7) |
| (8) |
| (9) |
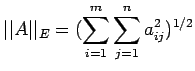
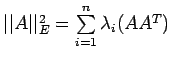 where n is the
order of
where n is the
order of 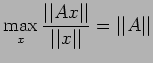
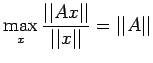
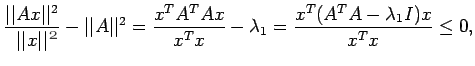
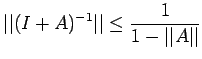
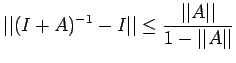
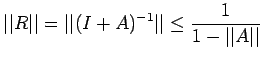
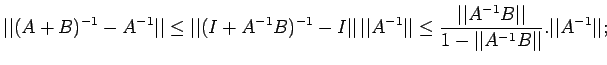
![$\displaystyle \leq \frac{\vert\vert A^{-1}\vert\vert}{1-\vert\vert A^{-1}\vert\...
...ert\vert A^{-1}\vert\vert\,\vert\vert b\vert\vert+\vert\vert\delta b\vert\vert]$](img280.png) |
(10) |
| (11) |
| (12) |
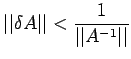 |
(13) |
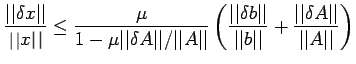
| (14) |
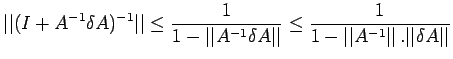
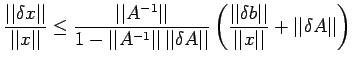
![$\displaystyle \frac{\vert\vert\delta x\vert\vert}{\vert\vert x\vert\vert}\leq \...
...b\vert\vert}+\frac{\vert\vert\delta A\vert\vert}{\vert\vert A\vert\vert}\right]$](img300.png) |
(15) |
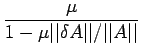
| (16) |
| (17) |
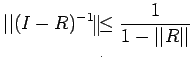
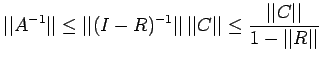

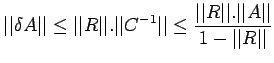
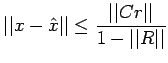
| (18) |
| (19) |
| (20) |
| (21) |
| (22) |
| (23) |
| (24) |
| (25) |
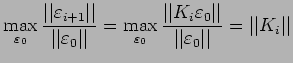
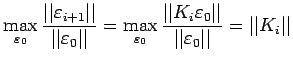 Therefore,
Therefore,
| (26) |
| (27) |
| (28) |
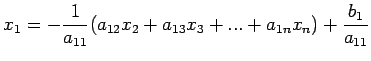
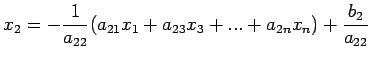 |
(29) |
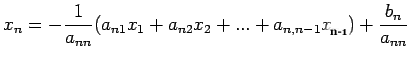
![\begin{displaymath}B=\left[%
\begin{array}{cccccc}
0 & -a_{12}/a_{11} & -a_{1...
...{nn} & . & . & -a_{n,n-1}/a_{nn} & 0 \\
\end{array}%
\right]\end{displaymath}](img371.png)
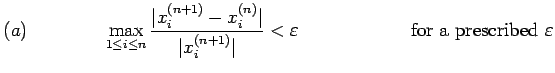
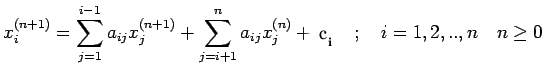
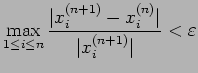 for some prescribed
for some prescribed | (30) |
| (31) |
| (32) |
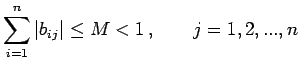 |
(33) |
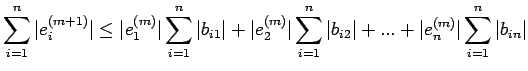

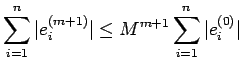
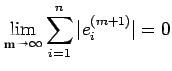
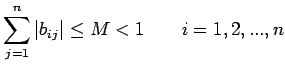 |
(34) |
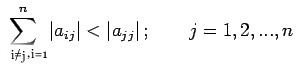 |
(35) |
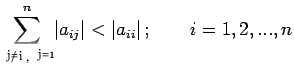 |
(36) |