

Contents
The Neural Network Used
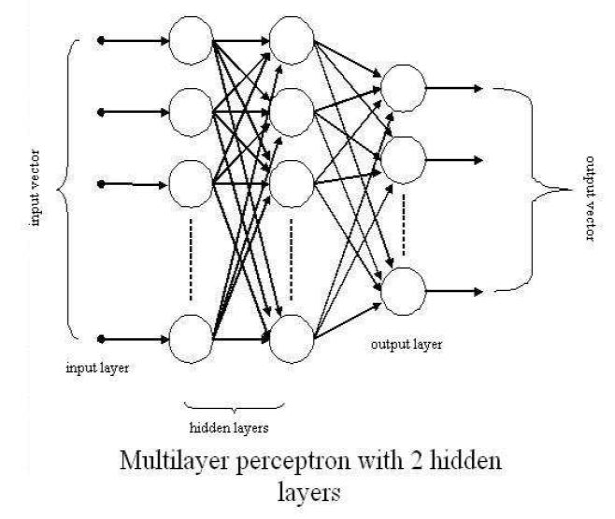
For our pattern recognition task, we shall consider a multilayer, feedforward (i.e. with no
feedback loops) neural network, as depicted in the figure below. It has an input layer
(where the external input vector is applied to the network), an output layer (of neurons,
whose outputs constitute the output of the network) and intermediate hidden layers of
neurons. We will consider a fully connected network, in which the output of each neuron
in a hidden layer is applied to every neuron in the next layer. Such a network is also
called a Multilayer Perceptron.
It is, at this stage beyond us to justify why such a structure of a neural network is
employed for our pattern recognition task. All we can say is, such networks are known to
do a good job, with suitable choice of synaptic weights and biasing parameters, and that
algorithms for evaluating these parameters optimally are known. We shall discuss in
detail one such training algorithm a little later, however, let us first make clear what
these algorithms do for us. We start off with a set of input vectors, and the corresponding
responses we expect from the system. For instance, with forex forecasting, if we have
determined that factors a, b, c and d determine tomorrow'sforex rate, we start off with a
set (typically large) of previously observed values of a, b, c and d and the
correspondingly observed forex rate of the next day. This constitutes what is called the
training data. The learning algorithms adjust the free parameters of the network so that
the responses of the network to the input samples in the training data are close to the
corresponding desired responses.
Now, once the training is done, what happens when the network is presented with an
input vector not encountered before during training? It is observed that under certain
conditions, the response of the neural network is actually close to the response we would
expect for that input. This property of the trained neural network is called generalization.
It is this generalization we rely on when we input, say today'svalues of the factors a, b, c,
and d to get a forecast of tomorrow'sforex rate. Neural networks are able to pick up very
complex dependencies of the dependent variable(s) on the independent variables (that
constitute the components of the input vector), and hence do a better job at function
extrapolation / interpolation than conventional regression techniques.
A natural thought arises: surely this kind of generalization must demand certain
conditions on the function involved and the training data used. The answer is yes, and
some of the intuitive conditions are:
1. The components of the input vector must be chosen, so that a dependence does in fact
exist, between these and the dependent variable. You obviously will not expect the
neural network to generalize well with incomplete input dependencies. For example,
to say the forex rate depends only on inflation rate and price index in the two countries
is of course grossly crude. Hence, if you train a network with only these as input
fields, you can't expect the network top redict forex rates accurately.
2. The data samples must be large in number and well spread over the input space.
3. The function involved must be smooth, i.e. a small change in one of the factors should
cause a small change in the dependent variable. An arbitrary function obviously can't
be estimated from its samples!
Now, we move on to a study of the Back Propagation Algorithm, one of the algorithms
used to train a multilayer feedforward neural network.

