| |
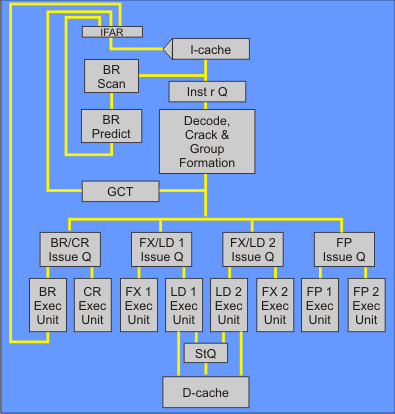
POWER4 core
- 8-wide fetch, 8-wide issue, 5-wide commit
- Features out-of-order issue with renaming and branch prediction (bimodal+gshare hybrid)
- Allows 20 groups of at most 5 instructions each to be in-flight beyond dispatch (100 instructions)
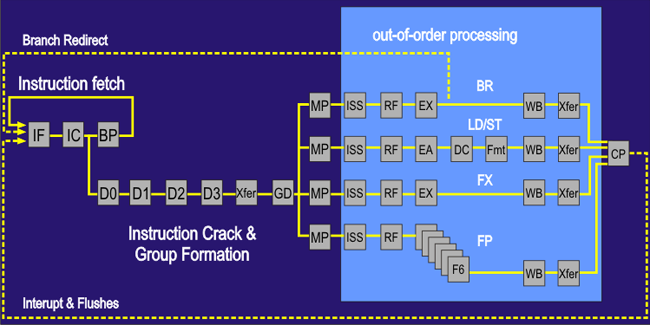
POWER4 pipeline
- Relatively short pipe
- Clocked at more than 1 GHz for 0.18μm technology
- Minimum 15 cycles for integer instructions
- Minimum 12-cycle branch misprediction penalty
- 11 small parallel issue queues (divided into four groups) for fast selection
- Back-to-back issue of dependent instructions not allowed: slow bypass or bypass absent? Requires at least one cycle gap
- Out-of-order load issue, load-load and load-store replay; load-load replay optimized with load queue snoop bit
- Write through write no allocate private L1 data cache; at most 8 outstanding L1 load misses
- Inclusion maintained between L2 and L1
|
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
|
|
|
|