| |
Performance issues
- Latency optimizations
- Reduce transactions on critical path: 3-hop vs. 4-hop
- Overlap activities: protocol processing and data access, invalidations, invalidation acknowledgments
- Make critical path fast: directory cache, integrated memory controller, smart protocol
- Reduce occupancy of protocol engine
- Throughput optimizations
- Pipeline the protocol processing
- Multiple coherence engines
- Protocol decisions: where to collect invalidation acknowledgments, existence of clean replacement hints
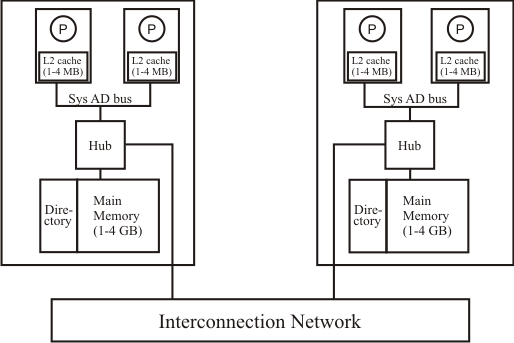
SGI Origin 2000
- Similar to Stanford DASH
- Flat memory-based directory organization
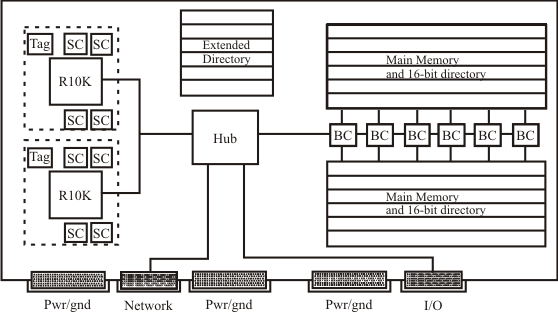
Connections to Backplane
- Directory state in separate DRAMs, accessed in parallel with data
- Up to 512 nodes (1024 processors)
- 195 MHz MIPS R10k (peak 390 MFLOPS and 780 MIPS per processor)
- Peak SysADBus (64 bits) bandwidth is 780 MB/s; same for hub-memory
- Hub to router and Xbow (I/O processor) is 1.56 GB/s
- Hub is 500 K gates in 0.5 micron CMOS
- Outstanding transaction buffer (aka CRB): 4 per processor
- Two processors per node are not snoop-coherent
|
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
|
|
|
|