| |
Four organizations
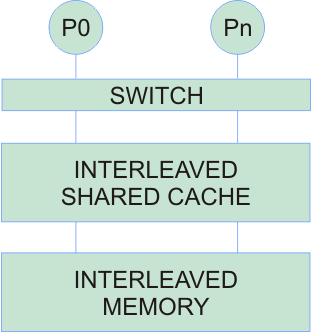
- Shared cache
- The switch is a simple controller for granting access to cache banks
- Interconnect is between the processors and the shared cache
- Which level of cache hierarchy is shared depends on the design: Chip multiprocessors today normally share the outermost level (L2 or L3 cache)
- The cache and memory are interleaved to improve bandwidth by allowing multiple concurrent accesses
- Normally small scale due to heavy bandwidth demand on switch and shared cache
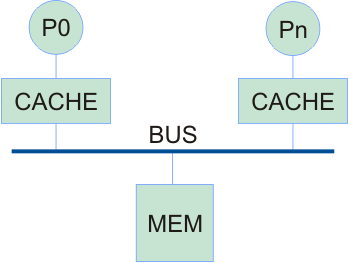
- Bus-based SMP
- Scalability is limited by the shared bus bandwidth
- Interconnect is a shared bus located between the private cache hierarchies and memory controller
- The most popular organization for small to medium-scale servers
- Possible to connect 30 or so processors with smart bus design
- Bus bandwidth requirement is lower compared to shared cache approach
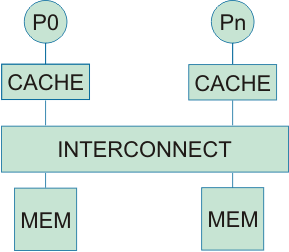
- Dancehall
- Better scalability compared to previous two designs
- The difference from bus-based SMP is that the interconnect is a scalable point-to-point network (e.g. crossbar or other topology)
- Memory is still symmetric from all processors
- Drawback: a cache miss may take a long time since all memory banks too far off from the processors (may be several network hops)
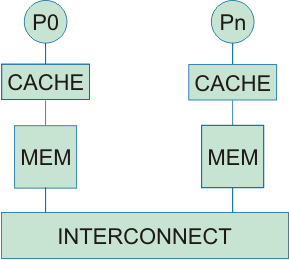
- Distributed shared memory
- The most popular scalable organization
- Each node now has local memory banks
- Shared memory on other nodes must be accessed over the network
- Non-uniform memory access (NUMA)
- Latency to access local memory is much smaller compared to remote memory
- Caching is very important to reduce remote memory access
- In all four organizations caches play an important role in reducing latency and bandwidth requirement
- If an access is satisfied in cache, the transaction will not appear on the interconnect and hence the bandwidth requirement of the interconnect will be less (shared L1 cache does not have this advantage)
- In distributed shared memory (DSM) cache and local memory should be used cleverly
- Bus-based SMP and DSM are the two designs supported today by industry vendors
- In bus-based SMP every cache miss is launched on the shared bus so that all processors can see all transactions
- In DSM this is not the case
|
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
|
|
|
|