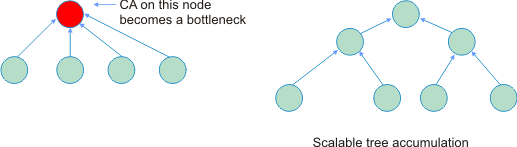
- Given the total volume of communication (in bytes, say) the goal is to reduce the end-to-end latency
- Simple model:
T = f*(o + L + (n / m) / B + tc – overlap) where
f = frequency of messages
o = overhead per message (at receiver and sender)
L = network delay per message (really the router delay)
n = total volume of communication in bytes
m = total number of messages
B = node-to-network bandwidth
tc = contention-induced average latency per message
overlap = how much communication time is overlapped with useful computation