| |
Spatial locality
- Consider a square block decomposition of grid solver and a C-like row major layout i.e. A[i][j] and A[i][j+1] have contiguous memory locations
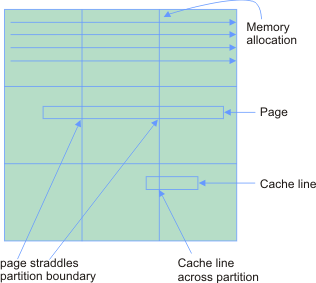 |
The same page is local to a processor while remote to others; same applies to straddling cache lines. Ideally, I want to have all pages within a partition local to a single processor. Standard trick is to covert the 2D array to 4D. |
2D to 4D conversion
- Essentially you need to change the way memory is allocated
- The matrix A needs to be allocated in such a way that the elements falling within a partition are contiguous
- The first two dimensions of the new 4D matrix are block row and column indices i.e. for the partition assigned to processor P6 these are 1 and 2 respectively (assuming 16 processors)
- The next two dimensions hold the data elements within that partition
- Thus the 4D array may be declared as float B[√P][√P][N/√P][N/√P]
- The element B[3][2][5][10] corresponds to the element in 10th column, 5th row of the partition of P14
- Now all elements within a partition have contiguous addresses
- Clearly, naming requires some support from hw and OS
- Need to make sure that the accessed virtual address gets translated to the correct physical address
Transfer granularity
- How much data do you transfer in one communication?
- For message passing it is explicit in the program
- For shared memory this is really under the control of the cache coherence protocol: there is a fixed size for which transactions are defined (normally the block size of the outermost level of cache hierarchy)
- In shared memory you have to be careful
- Since the minimum transfer size is a cache line you may end up transferring extra data e.g., in grid solver the elements of the left and right neighbors for a square block decomposition (you need only one element, but must transfer the whole cache line): no good solution
|
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
|
|
|
|