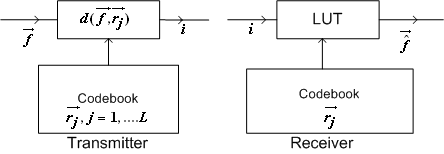
Computational and storage requirements of designing a codebook using k-means algorithm:
The most computationally expensive part of the k-means algorithm is the quantization of training vectors in each iteration.
For each of M training vectors, the distortion measure must be evaluated L times (one for each iteration), So ML evaluations of distortion measure are necessary in each iteration.
Assuming there are N scalars in a vector, R bits used per scalar and a uniform length codeword is assigned to each reconstruction level, then
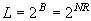 where B is the total number of bits per vector. where B is the total number of bits per vector.
If we further assume that the distortion measure used is squared error 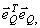 Number of
arithmetic operations= NML=NM2NR Number of
arithmetic operations= NML=NM2NR
This shows that the computational cost grows exponentially with N. If N=10, R=2 and M=10L=10.2NR=10.210, the number of arithmetic operations is given by 100 trillion per iteration.
In addition to computational cost there is also storage cost.Assuming each scalar requires are
unit of memory, then total number of memory units required is = (M+L)N=(M+2NR)N.
Since M is typically much greater than L, memory requirements are dominated by storage of training vectors.
Once the codebook is designed, it must be stored at both the transmitter and receiver. Since the training vectors are no longer needed once the codebook is designed, only the reconstruction levels need to be stored. In this number of memory units required in a codebook is 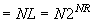
For N=10, R=2, this is of the order of 10 million. For each vector
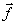 to be quantised, the
distortion measure
to be quantised, the
distortion measure 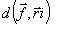 has to be computed for each of the L reconstruction levels at the transmitter. Therefore for each vector, has to be computed for each of the L reconstruction levels at the transmitter. Therefore for each vector, Number of arithmetic operations .
It is observed that the number of
arithmetic operations as well as Number of memory units required to quantise
one vector 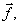 grow exponentially with N (scalars per vector) and R (bits/pixel). The above arithmetic operations are required at the transmitter. grow exponentially with N (scalars per vector) and R (bits/pixel). The above arithmetic operations are required at the transmitter.
At the receiver only a simple table looks up operations are required. This is shown schematically below.
|