An Iterative Procedure for designing an optimal codebook.
Suppose we begin with an initial estimate of 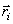 .Given and the distortion
measure, .Given and the distortion
measure,
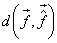 we can determine Ci, at least in theory, by determining the corresponding we can determine Ci, at least in theory, by determining the corresponding 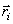 for all possible
values of for all possible
values of 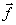 using condition (1).Given an estimate of Ci, we can determine using condition (1).Given an estimate of Ci, we can determine 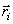 by computing the
centroid of Ci using condition (2). The by computing the
centroid of Ci using condition (2). The 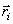 obtained is a new estimate of the reconstruction levels and
the procedure is continued. The iterative procedure has two difficulties:
(i) Requires the determination of obtained is a new estimate of the reconstruction levels and
the procedure is continued. The iterative procedure has two difficulties:
(i) Requires the determination of 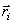 for all possible for all possible 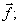 and
(ii) The probability density function and
(ii) The probability density function 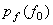 required to compute
centroid of Ci is usually not known. Instead we have training vectors that are representative of the data to be coded. A modification of this method is the k-means algorithm. required to compute
centroid of Ci is usually not known. Instead we have training vectors that are representative of the data to be coded. A modification of this method is the k-means algorithm.
K-Means Algorithm:-
To describe the k-means algorithm, let us suppose we have M-training vectors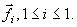 Since we estimate L
reconstruction levels from M training vectors, we assume Since we estimate L
reconstruction levels from M training vectors, we assume 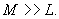 Typically M is of the order of 10L to 50L or more. Typically M is of the order of 10L to 50L or more.
Randomly selecting the initial codevectors from the training set often does not provide sufficient diversity to achieve a good locally optimal codebook. It is often effective to choose initial codevectors from training set that are farthest apart in terms of distortion measure. This assures initial codevectors are widely distributed in N-dimensional space.
The reconstruction levels 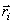 are determined by minimizing average distortion are determined by minimizing average distortion 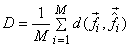 .In the k-means algorithm we begin with an initial estimate of .In the k-means algorithm we begin with an initial estimate of 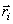 for for 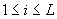 . .
We then classify the M training vectors into L-different groups or clusters, corresponding to each reconstruction level using condition (1).
This can be done by comparing a training vector with each 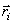
and choosing the level that result in a minimum distortion.
It is to be noted that we quantise only the given training vector, not all possible vectors 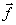 . A new reconstruction level is determined from the vectors in each cluster. . A new reconstruction level is determined from the vectors in each cluster.
|