Problems in SLR parsing
. No sentential form of this grammar can start with R=.
. However, the reduce action in action[2,=] generates a sentential form starting with R=
. Therefore, the reduce action is incorrect
. In SLR parsing method state i calls for reduction on symbol "a", by rule A 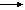 α if I i contains [A α.] and "a" is in follow(A)
α if I i contains [A α.] and "a" is in follow(A)
. However, when state I appears on the top of the stack, the viable prefix ßα on the stack may be such that ß A can not be followed by symbol "a" in any right sentential form
. Thus, the reduction by the rule A α on symbol "a" is invalid
. SLR parsers cannot remember the left context
The reason for the above is that in derivation which gave an error, if we inspect the stack while reducing for [2,=], it would generate a sentential form 'R='which is incorrect as can be seen from the productions. Hence using the reduce action is incorrect and other one is the correct derivation. So, the grammar is not allowing multiple derivations for [2,=] and thus, is unambiguous.
The reason why using this reduction is incorrect is due to limitation of SLR parsing. A reduction is done in SLR parsing on symbol b in state i using rule A a if b is in follow(A) and I i contains [A a.] but it might be possible that viable prefix on stack ß a may be such that ß A cannot be followed by 'b' in any right sentential form, hence doing the reduction is invalid.
So, in given example, in state 2 on symbol ' = ' , we can reduce using R L but the viable prefix is 0L which on reduction gives 0R, which cannot be followed by '=' in any right sentential form as can be seen from the grammar.
So, we can conclude SLR parsers cannot remember left context which makes it weak to handle all languages.