| |
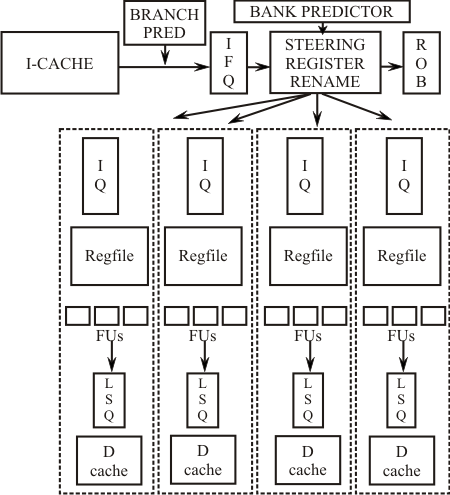
Clustered arch.
- An alternative to CMP is clustered microarchitecture
- Still tries to extract ILP and runs a single thread
- But divides the execution unit into clusters where each cluster has a separate register file
- Number of ports per register file goes down dramatically reducing the complexity
- Can even replicate/partition caches
- Big disadvantage: keeping the register file and cache partitions coherent; may need global wires
- Key factor: frequency of communication
- Also, standard problems of single-threaded execution remain: branch prediction, fetch bandwidth, etc.
May want to steer dependent instructions to the same
Cluster to minimize communication
ABCs of CMP
- Where to put the interconnect?
- Do not want to access the interconnect too frequently because these wires are slow
- It probably does not make much sense to have the L1 cache shared among the cores: requires very high bandwidth and may necessitate a redesign of the L1 cache and surrounding load/store unit which we do not want to do; so settle for private L1 caches, one per core
- Makes more sense to share the L2 or L3 caches
- Need a coherence protocol at L2 interface to keep private L1 caches coherent: may use a high-speed custom designed snoopy bus connecting the L1 controllers or may use a simple directory protocol
- An entirely different design choice is not to share the cache hierarchy at all (dual-core AMD and Intel): rids you of the on-chip coherence protocol, but no gain in communication latency
Shared cache design
- Need to be banked
- How many coherence engines per bank?
- Notion of home bank? Miss in home bank means what?
- Snoop or directory?
- COMA with home bank?
Hierarchical MP
- SMT and CMP add couple more levels in hierarchical multiprocessor design
- If you just have an SMT processor, among the threads you can do shared memory multiprocessing with possibly the fastest communication; you can connect the SMT processors to build an SMP over a snoopy bus; you can connect these SMP nodes over a network with a directory protocol
- Can do the same thing with CMP, only difference is that you need to design the on-chip coherence logic (that is not automatically enforced as in SMT)
- If you have a CMP with each core being an SMT, then you really have a tall hierarchy of shared memory; the communication becomes costlier as you go up the hierarchy; also communication becomes very much non-uniform
|
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
|
|
|
|