| |
PC and PSO
- Processor consistency (PC) is same as TSO, but does not guarantee write atomicity
- The writes may become visible to different processors in different order
- P0: A=1; P1: while (!A); B=1; P2: while (!B); print A;
- BTW, how can a system not guarantee write atomicity? What hardware logics you get rid of by not implementing write atomicity?
- Implemented in Intel processors
- Partial store ordering (PSO) allows reads as well as writes to bypass writes
- Still implements write atomicity like TSO
- Further overlaps write latency
- Deviates a lot from SC (flag spinning no longer works)
- Store barrier instruction is needed to “emulate” SC
TSO, PC, PSO
- Hardware support
- TSO and PC still need to worry about load-invalidate squash (why?)
- In TSO and PC the store queue entries are freed in-order because stores are not allowed to bypass stores
- A processor supporting PSO can retire stores in any order (however, a store cannot bypass a load)
- The store barrier instruction (stbar in SPARC) goes through the normal store queue and controls issuing of future store instructions
- Note that in all three models memory operations to the same or overlapping addresses must issue in program order
- All three models may benefit from bigger write/store buffers
Weak ordering (WO)
- First seminal relaxed consistency model; also known as weak consistency
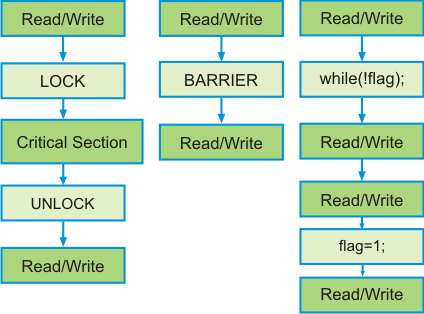
- An important observation is that a parallel programmer does not really care about ordering among memory operations between synchronizations as long as conventional data and control dependencies are preserved within a process
- For example, within a critical section the exact order in which independent reads/writes are executed is not important
- Weak ordering makes use of this property and relaxes all memory orders between synchronization operations e.g., within and outside critical sections, between consecutive barriers, before and after flag synchronization
- A few constraints must be followed
- Any code from outside a critical section cannot be re-ordered with codes inside the critical section i.e. all codes before a critical section must commit before lock is acquired, all codes within a critical section must commit before releasing the lock, and any code after a critical section must not issue before releasing the lock
- Any code before a barrier must commit before entering a barrier and any code after a barrier must not issue before leaving the barrier (second condition should hold naturally if barrier implementation itself is same)
- Any code before flag wait must commit before waiting on the flag, any code after flag wait must not issue before the flag is set by producer, any code before setting of a flag must commit before setting the flag, and any code after setting of flag must not issue before setting of flag
- Perfectly suits modern microprocessors and aggressive compiler optimizations
- Either hardware must be able to recognize synchronization operations and stall until everything before it has graduated or compiler must insert proper memory barrier instructions
- MIPS R10000 provides a sync instruction and a fence count register for this purpose; fence count register is incremented whenever an L2 miss leaves the chip and decremented on a reply; a sync instruction disables issuing from address queue until fence register is zero and all outstanding memory operations have committed
- A processor supporting WO does not need to have load-invalidate squash as in the MIPS R10000
|
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
|
|
|
|