| |
Scaling bandwidth
- Data bandwidth
- Make the bus wider: costly hardware
- Replace bus by point-to-point crossbar: since only the address portion of a transaction is needed for coherence, the data transaction can be directly between source and destination
- Add multiple data busses
- Snoop or coherence bandwidth
- This is determined by the number of snoop actions that can be executed in unit time
- Having concurrent non-conflicting snoop actions definitely helps improve the protocol throughput
- Multiple address busses: a separate snoop engine is associated with each bus on each node
- Order the address busses logically to define a partial order among concurrent requests so that these partial orders can be combined to form a total order
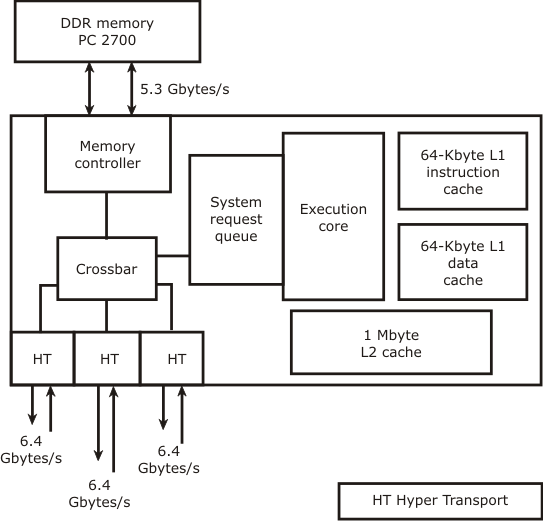
AMD Opteron
- Each node contains an x86-64 core, 64 KB L1 data and instruction caches, 1 MB L2 cache, on-chip integrated memory controller, three fast routing links called hyperTransport, local DDR memory
- Glueless MP: just connect 8 Opteron chips via HT to design a distributed shared memory multiprocessor
- L2 cache supports 10 outstanding misses
- Integrated memory controller and north bridge functionality help a lot
- Can clock the memory controller at processor frequency (2 GHz)
- No need to have a cumbersome motherboard; just buy the Opteron chip and connect it to a few peripherals (system maintenance is much easier)
- Overall, improves performance by 20-25% over Athlon
- Snoop throughput and bandwidth is much higher since the snoop logic is clocked at 2 GHz
- Integrated hyperTransport provides very high communication bandwidth
- Point-to-point links, split-transaction and full duplex (bidirectional links)
- On each HT link you can connect a processor or I/O
|
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
|
|
|
|