| |
Design issues
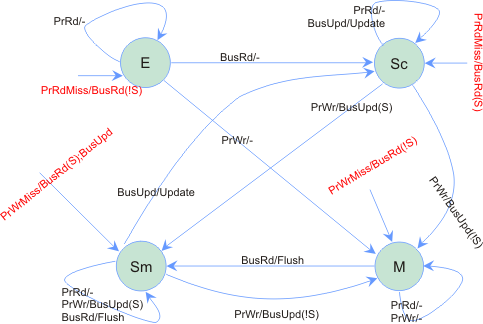
Dragon example
- Take the following sequence
- P0 reads x, P1 reads x, P1 writes x, P0 reads x, P2 reads x, P3 writes x
- P0 generates BusRd, shared line remains low, it puts line in E state
- P1 generates BusRd, shared line is asserted by P0, P1 puts line in Sc state, P0 also transitions to Sc state
- P1 generates BusUpd, P0 asserts shared line, P1 takes the line to Sm state, P0 applies update but remains in Sc
- P0 reads from cache, no state transition
- P2 generates BusRd, P0 and P1 assert shared line, P1 sources the line on bus, P2 puts line in Sc state, P1 remains in Sm state, P0 remains in Sc state
- P3 generates BusRd followed by BusUpd, P0, P1, P2 assert shared line, P1 sources the line on bus, P3 puts line in Sm state, line in P1 goes to Sc state, lines in P0 and P2 remain in Sc state, all processors update line
Design issues
- Can we eliminate the Sm state?
- Yes. Provided on every BusUpd the memory is also updated; then the Sc state is sufficient (essentially boils down to a standard MSI update protocol)
- However, update to cache may be faster than memory; but updating cache means occupying data banks during update thereby preventing the processor from accessing the cache, so not to degrade performance, extra cache ports may be needed
- Is it necessary to launch a bus transaction on an eviction of a line in Sc state?
- May help if this was the last copy of line in Sc state
- If there is a line in Sm state, it can go back to M and save subsequent unnecessary BusUpd transactions (the shared wire already solves this)
General issues
- Thus far we have assumed an atomic bus where transactions are not interleaved
- In reality, high performance busses are pipelined and multiple transactions are in progress at the same time
- How do you reason about coherence?
- Thus far we have assumed that the processor has only one level of cache
- How to extend the coherence protocol to multiple levels of cache?
- Normally, the cache coherence protocols we have discussed thus far executes only on the outermost level of cache hierarchy
- A simpler but different protocol runs within the hierarchy to maintain coherence
- We will revisit these questions soon
Evaluating protocols
- In message passing machines the design of the message layer plays an important role
- Similarly, cache coherence protocols are central to the design of a shared memory multiprocessor
- The protocol performance depends on an array of parameters
- Experience and intuition help in determining good design points
- Otherwise designers use workload-driven simulations for cost/performance analysis
- Goal is to decide where to spend money, time and energy
- The simulators model the underlying multiprocessor in enough detail to capture correct performance trends as one explores the parameter space
|
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
|
|
|
|