| |
MSI protocol
- Forms the foundation of invalidation-based writeback protocols
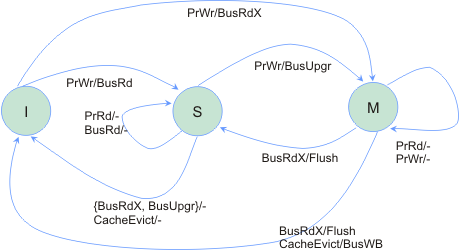
- Assumes only three supported cache line states: I, S, and M
- There may be multiple processors caching a line in S state
- There must be exactly one processor caching a line in M state and it is the owner of the line
- If none of the caches have the line, memory must have the most up-to-date copy of the line
- Processor requests to cache: PrRd, PrWr
- Bus transactions: BusRd, BusRdX, BusUpgr, BusWB
State transition
MSI protocol
- Few things to note
- Flush operation essentially launches the line on the bus
- Processor with the cache line in M state is responsible for flushing the line on bus whenever there is a BusRd or BusRdX transaction generated by some other processor
- On BusRd the line transitions from M to S, but not M to I. Why? Also at this point both the requester and memory pick up the line from the bus; the requester puts the line in its cache in S state while memory writes the line back. Why does memory need to write back?
- On BusRdX the line transitions from M to I and this time memory does not need to pick up the line from bus. Only the requester picks up the line and puts it in M state in its cache. Why?
M to S, or M to I?
- BusRd takes a cache line in M state to S state
- The assumption here is that the processor will read it soon, so save a cache miss by going to S
- May not be good if the sharing pattern is migratory: P0 reads and writes cache line A, then P1 reads and writes cache line A, then P2…
- For migratory patterns it makes sense to go to I state so that a future invalidation is saved
- But for bus-based SMPs it does not matter much because an upgrade transaction will be launched anyway by the next writer, unless there is special hardware support to avoid that: how?
- The big problem is that the sharing pattern for a cache line may change dynamically: adaptive protocols are good and are supported by Sequent Symmetry and MIT Alewife
MSI example
- Take the following example
- P0 reads x, P1 reads x, P1 writes x, P0 reads x, P2 reads x, P3 writes x
- Assume the state of the cache line containing the address of x is I in all processors
P0 generates BusRd, memory provides line, P0 puts line in S state
P1 generates BusRd, memory provides line, P1 puts line in S state
P1 generates BusUpgr, P0 snoops and invalidates line, memory does not respond, P1 sets state of line to M
P0 generates BusRd, P1 flushes line and goes to S state, P0 puts line in S state, memory writes back
P2 generates BusRd, memory provides line, P2 puts line in S state
P3 generates BusRdX, P0, P1, P2 snoop and invalidate, memory provides line, P3 puts line in cache in M state
|
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
|
|
|
|