| |
Snoopy protocols
- Cache coherence protocols implemented in bus-based machines are called snoopy protocols
- The processors snoop or monitor the bus and take appropriate protocol actions based on snoop results
- Cache controller now receives requests both from processor and bus
- Since cache state is maintained on a per line basis that also dictates the coherence granularity
- Cannot normally take a coherence action on parts of a cache line
- The coherence protocol is implemented as a finite state machine on a per cache line basis
- The snoop logic in each processor grabs the address from the bus and decides if any action should be taken on the cache line containing that address (only if the line is in cache)
Write through caches
- There are only two cache line states
- Invalid (I): not in cache
- Valid (V): present in cache, may be present in other caches also
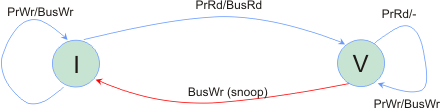
- Read access to a cache line in I state generates a BusRd request on the bus
- Memory controller responds to the request and after reading from memory launches the line on the bus
- Requester matches the address and picks up the line from the bus and fills the cache in V state
- A store to a line always generates a BusWr transaction on the bus (since write through); other sharers either invalidate the line in their caches or update the line with new value
State transition
- The finite state machine for each cache line:
- On a write miss no line is allocated
- The state remains at I: called write through write no-allocated
- A/B means: A is generated by processor, B is the resulting bus transaction (if any)
- Changes for write through write allocate?
Ordering memory op
- Assume that the bus is atomic
- It takes up the next transaction only after finishing the previous one
- Read misses and writes appear on the bus and hence are visible to all processors
- What about read hits?
- They take place transparently in the cache
- But they are correct as long as they are correctly ordered with respect to writes
- And all writes appear on the bus and hence are visible immediately in the presence of an atomic bus
- In general, in between writes reads can happen in any order without violating coherence
- Writes establish a partial order
Write through is bad
- High bandwidth requirement
- Every write appears on the bus
- Assume a 3 GHz processor running application with 10% store instructions, assume CPI of 1
- If the application runs for 100 cycles it generates 10 stores; assume each store is 4 bytes; 40 bytes are generated per 100/3 ns i.e. BW of 1.2 GB/s
- A 1 GB/s bus cannot even support one processor
- There are multiple processors and also there are read misses
- Writeback caches absorb most of the write traffic
- Writes that hit in cache do not go on bus (not visible to others)
- Complicated coherence protocol with many choices
|
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
|
|
|
|