| |
Dataflow architecture
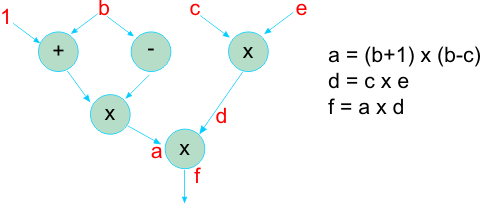
- Express the program as a dataflow graph
- Logical processor at each node is activated when both operands are available
- Mapping of logical nodes to PEs is specified by the program
- On finishing an operation, a message or token is sent to the destination processor
- Arriving tokens are matched against a token store and a match triggers the operation
Systolic arrays
- Replace the pipeline within a sequential processor by an array of PEs
- Each PE may have small instruction and data memory and may carry out a different operation
- Data proceeds through the array at regular “heartbeats” (hence the name)
- The dataflow may be multi-directional or optimized for specific algorithms
- Optimize the interconnect for specific application (not necessarily a linear topology)
- Practical implementation in iWARP
- Uses general purpose processors as PEs
- Dedicated channels between PEs for direct register to register communication
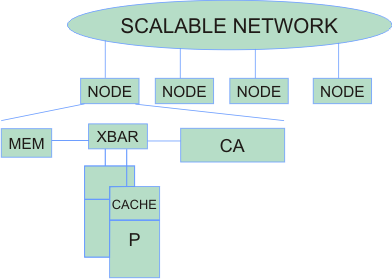
A generic architecture
- In all the architectures we have discussed thus far a node essentially contains processor(s) + caches, memory and a communication assist (CA)
- CA = network interface (NI) + communication controller
- The nodes are connected over a scalable network
- The main difference remains in the architecture of the CA
- And even under a particular programming model (e.g., shared memory) there is a lot of choices in the design of the CA
- Most innovations in parallel architecture take place in the communication assist (also called communication controller or node controller)
|
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
|
|
|
|