In this example, instruction 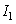 is fetched from the cache in cycle 1 and its execution proceeds normally.
is fetched from the cache in cycle 1 and its execution proceeds normally.
The fetch operation for instruction 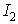 which starts in cycle 2, results in a cache miss.
which starts in cycle 2, results in a cache miss.
The instruction fetch unit must now suspend any further fetch requests and wait for to arrive.
We assume that instruction is received and loaded into buffer B1 at the end of cycle 5, It appears that cache memory used here is four time faster than the main memory.
The pipeline resumes its normal operation at that point and it will remain in normal operation mode for some times, because a cache miss generally transfer a block from main memory to cache.
From the figure, it is clear that Decode unit, Operate unit and Write unit remain idle for three clock cycle.
Such idle periods are sometimes referred to as bubbles in the pipeline.
Once created as a result of a delay in one of the pipeline stages, a bubble moves downstream until it reaches the last unit. A pipeline can not stall as long as the instructions and data being accessed reside in the cache. This is facilitated by providing separate on chip instruction and data caches.